Visualizing programming language communities
For the past couple of weeks, I have been working on visualizing programming language communities. The result can be seen here: http://ghtorrent.org/netviz/. The graph visualizes language communities for any language identified by Github, using commits as the medium to identify project collaborations. This means that nodes represent projects (repositories) and edges represent a developer that committed on both nodes.
To build the visualization, I extracted all commits from base repositories (commits on forks are excluded) from the GHTorrent database, along with information about the project (e.g. language as identified by Github). The dataset I am using has:
- 17896778 commits in
- 553993 repositories with code written in
- 106 languages by
- 309838 developers.
How it works
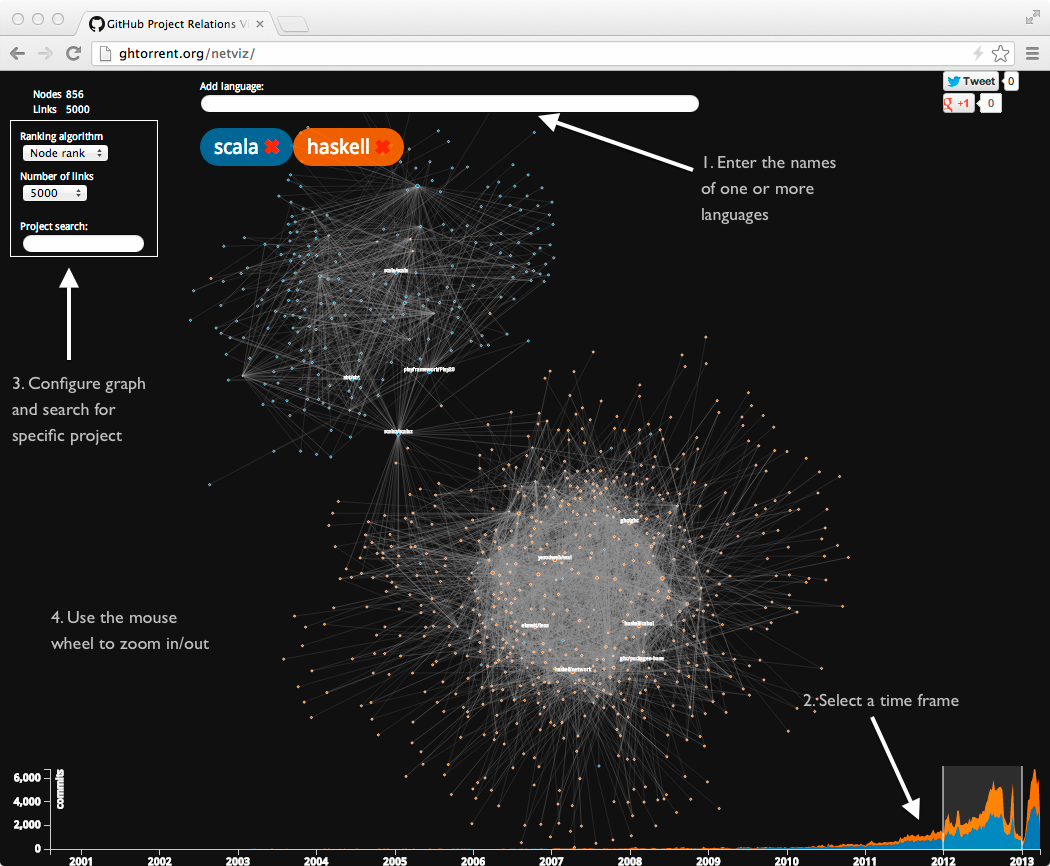
To start with the visualisation enter the name of your favourite programming language in the top level search box and wait a couple of seconds. A graph will start to move towards the center of the screen. It will usually look like a hair ball, because there are really too many connections among the projects, a good sing that developers are collaborating closely in the specific language ecosystem. What can you do next is:
- Search for your favourite project, on the side search field. Keep in mind that only the top projects by number of external contributions are being displayed, so the project you are looking for may not exist in the displayed graph.
- Zoom in or out (with the mouse wheel) and re-arrange the graph by dragging nodes around.
- Click on a node and see information about it along with a link to the original repository.
- Add a second language and see how the two language communities communicate. In the screen shot above, you can see that many Scala and Haskell hackers share a common interest in the Scalaz project.
- Extend/Reduce the timeframe or even move the slider little by little to see how each community evolved (or communities co-evolved).
- If your computer and browser is fast enough, you can increase the number of displayed links for a more realistic view (see below notes on graph stemming).
As the graphs are rendered and animated in real time, a fast browser and computer is required. On my 1.8GHz MacbookAir running Mountain Lion with Chrome 26, the threshold after which animation is becoming too slow is 5000 links and around 800 nodes. My 4 core Xeon 2.6Ghz desktop with Cromium on Debian Wheezy, animations are relatively fluid at 7500 links and 3000 nodes. Your mileage may vary.
How it was implemented
An interesting challenge of this project was how to process 18 million commits (or 1.4GB of condensed CSV data) on request in (soft) real time. For that, I exploited 2 properties of modern software systems: i) the abundance of RAM ii) the higher level data structure constructs present in modern languages. As I had good experience with the abstractions with my general purpose language of choice (Scala), I decided to construct an in-memory graph of the raw data, choosing the least memory intensive datatypes for each object (e.g., Ints instead of Doubles, references instead of Strings when those could be shared etc). Then, Scala’s parallel collections would automatically split the work load of processing (filtering, grouping etc) the in-memory graph to multiple CPU’s. The full set of commits fits in about 3GB of heap, while queries can be processed using all available processors. For typical languages, discovering the nodes and links takes less than 500 msec.
Due to the huge number of examined commits, queries on popular languages produce equally huge graphs. For example, querying for Ruby in the default time window will produce a graph consisting of 57889 nodes and 421312 edges. To filter the important nodes, I implemented two methods of node ranking:
- node degree ranking: Nodes are ranked based on the number of connections.
- pagerank: Nodes are ranked using the Pagerank algorithm. caveat: pagerank is meant to be used on directed graphs, while the produced graph is undirected.
After running the ranking algorithm, the graph is reconstructed by retrieving the top 100 (configurable) nodes by their rank and all edges that contain them. The reconstructed graph is further cleaned from nodes with in-degree of one and their edges (to eliminate visual noise). Again this might not be enough: at this stage our Ruby graph would still contain 3084 nodes and 62180 links. A hard limit of edges must be enforced: to do that, the algorithm sets a target number of links (by default, 5000) and randomly removes links from the graph, but it pays attention not to remove links that will leave orphaned nodes.
To visualize the results, I used the amazingly powerful d3js
library. My limited (read: non-existent) Javascript skills did not allow
me to write code that I am proud of, but using d3js was a pleasure. Instead
of relying on iteration and mutation, d3js uses arrays as collections and
higher order functions that operate on those. The result is a fluid API
that makes sense, after you get used to the underlying concepts. To that
end, the examples at the d3js gallery help a lot. Except from the initial data retrieval, all operations
happen at the client side. New data are retrieved only when a new language
has been added or the time window has changed.
The API
The API is open for use by anyone, so if you do not like this visualization, you
can build your own. The result format is JSON. The API is rooted at
http://ghtorrent.org/netviz/. The end points and parameters are the following:
/links: Get nodes and links in the format expected by d3js.
-
l: Languages to calculate links for. Multiple languages can be specified. Required. -
m: Method to do node ranking. Can have the following values:rank: the number of node connectionsjung: the jung library implementation of the pagerank algorithm (default)par: a parallel version of pagerank (slower that jung)
n: Number of nodes to select after ranking. Default: 100. Values more than 1000 will be truncated to 1000e: Number of edges to return. Default: 5000f: The epoch timestamp of the earliest commit to examine. Default: 0t: The epoch timestmap of the latest commit to examine: Default: 2^32
/hist: Number of commits per week for the languages in the argument:
l: Languages to calculate timebins for. Multiple languages can be specified Required.
/langs: A list of languages recognized by the system
Examples
http://ghtorrent.org/netviz/links?l=scala&l=clojure: This will return the
graph for the whole lifetime of the data set, for the languages Scala and
Clojure constrained to 5000 edges
http://ghtorrent.org/netviz/links?l=scala&m=jung&f=1322611200e=10000: This will return the
graph for scala, constrained to 10000 edges, ranked by Pagerank for commits
after 1/1/2012.
Availability
As always, you can find the source code on Github: gousiosg/ghtorrent-netviz. Please file issues and requests using the project’s issue tracker instead of using this blog’s comments.