Monitoring Github projects with GHTorrent
GHTorrent started as an effort to bring the rich data offered by the Github API to the hands of the Mining Software Repositories community. Recently, I have been working to make GHTorrent more accessible to all Github users. As of version 0.7.2, GHTorrent can run in standalone mode, using SQLite as its main database, thus doing away with the complicated setup required to mirror in a distributed fashion.
In this blog post, I describe how to setup GHTorrent in order to retrieve all metadata for a relatively small, but non-trivial, repository: Netflix’s RxJava (incidentally, this is also one of my favourite projects). Using the data from this project, I also created a couple of plots to give you an idea of what can be achieved with the data that GHTorrent gathers.
Setup and running
GHTorrent is distributed as a Ruby gem, and runs on Ruby 1.9.3. If you have an
older version of Ruby, use RVM to install 1.9.3 (rvm install
1.9.3) and make it default (rvm use 1.9.3). Installing GHTorrent is then
trivial:
gem install sqlite3 ghtorrent
Normally, GHTorrent is run in parallel on many machines, so it is convenient
that its configuration is file based. For our standalone setup, this might
be an annoyance, but we need to create a config.yaml file for GHTorrent to
run:
sql:
url: sqlite://github.db
mirror:
persister: noop
cache_mode: all
username: github_username
passwd: github_passwdMake sure you change username and password to your Github credentials. The
configuration file instructs GHTorrent to create an SQLite database in the
local directory, using no persister (this is to avoid installing MongoDB)
and full caching, thus making each request only once. We can control more
parameters of how GHTorrent works using more configuration options but the above
should be enough to get us started.
Then, we need to run the following command:
ght-retrieve-repo -c config.yaml Netflix RxJava
We see GHTorrent going though commits, pull requests, issues, watchers and other Github API entities. Lots of debug statements will be printed on the screen. You will see lots of duplicate work being done as well; this is the price to pay for not installing MongoDB as an intelligent caching layer. Nevertheless, half an hour later or so, we have in our directory an SQLite database with lots of interesting data representing the project’s life time.
Project process monitoring
The database schema is relatively
complicated, but the data it stores is very rich in return.
Using this database, we can formulate complex queries that will return
interesting insights of our project’s development process, including
some that were not possible without Github’s data. Below, I
present a couple of such queries, plotted using R and ggplot2.
You can find the R script here.
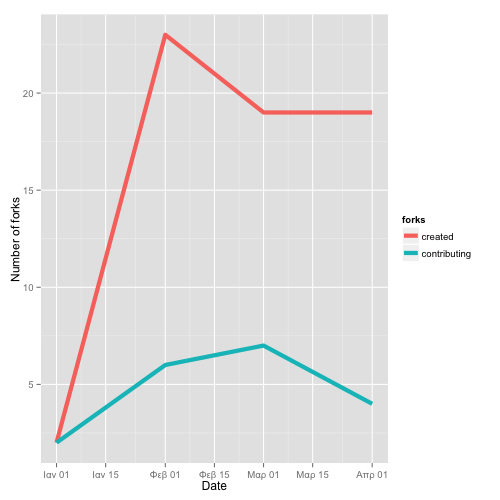
-
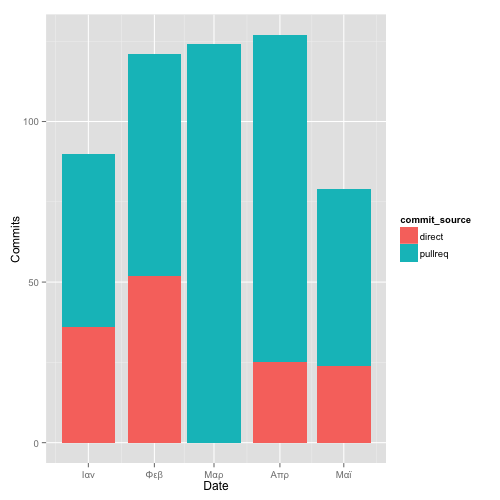
(3) Source of commits (query). The more commits come from pull requests, the more open the project process.
-
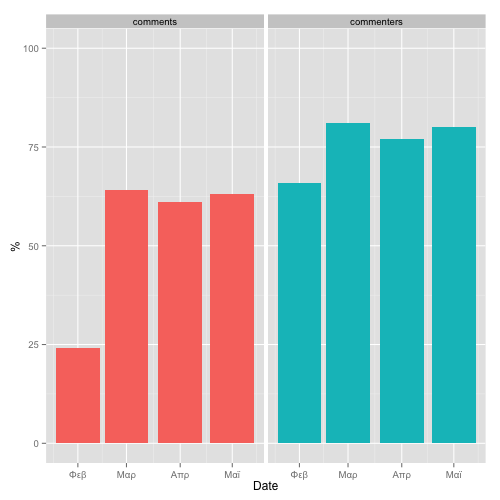
(5) Percentage of issue comments and commenters coming from the project community (i.e. users with no commit rights to the main repo)(query)
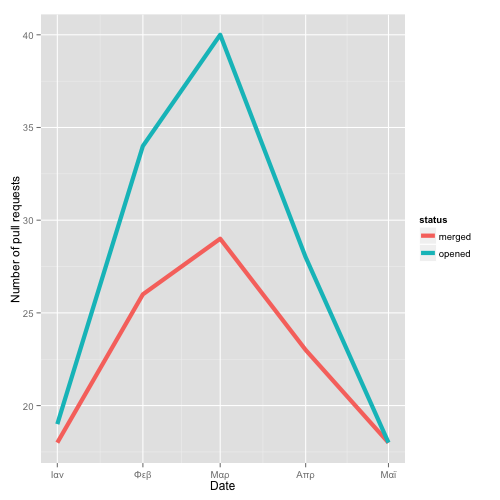
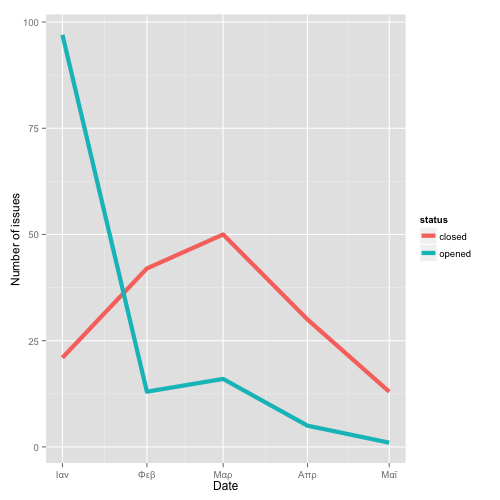
That’s it! Using a simple process, we can retrieve a very rich dataset to create
project specific reports from. What’s more is that the database can be updated
(make sure that cache: prod in config.yaml), and the report generation process can be automated. More than one projects can share the same database,
so organizations can have a centralized way of retrieving process information
about their projects. Researchers interested in doing work with Github’s data
can use this process to try out ideas on smaller projects before moving
forward to the real dataset.
Do you have any ideas for more useful reports? Leave a comment and I ‘ll promise to implement them!