On commit sizes and programming language expressiveness
Donnie Berkholz’s blog post on the expressiveness of programming languages has generated quite some online buzz. In this post, Donnie used the Ohloh dataset to rank programming languages by their expressiveness, as it can be approximated by the number of lines per commit in projects written in this language. The details of what data did the author process are not provided, xor a minor comment by the author as a response to another comment.
In our paper (missing reference) (missing reference) (missing reference) (missing reference) (missing reference) (missing reference) (missing reference), Diomidis and I had included a similar plot (even though for different reasons). To do it, we used data from the GHTorrent projects, namely around 8.5 million commits. For each commit, we extracted the number of lines for changed files; that is, we did not account for files being introduced to or being removed from the project. We did the matching of lines changed to language used on a per file basis, by guessing the language by the file extension). The results can be seen in the following figure:
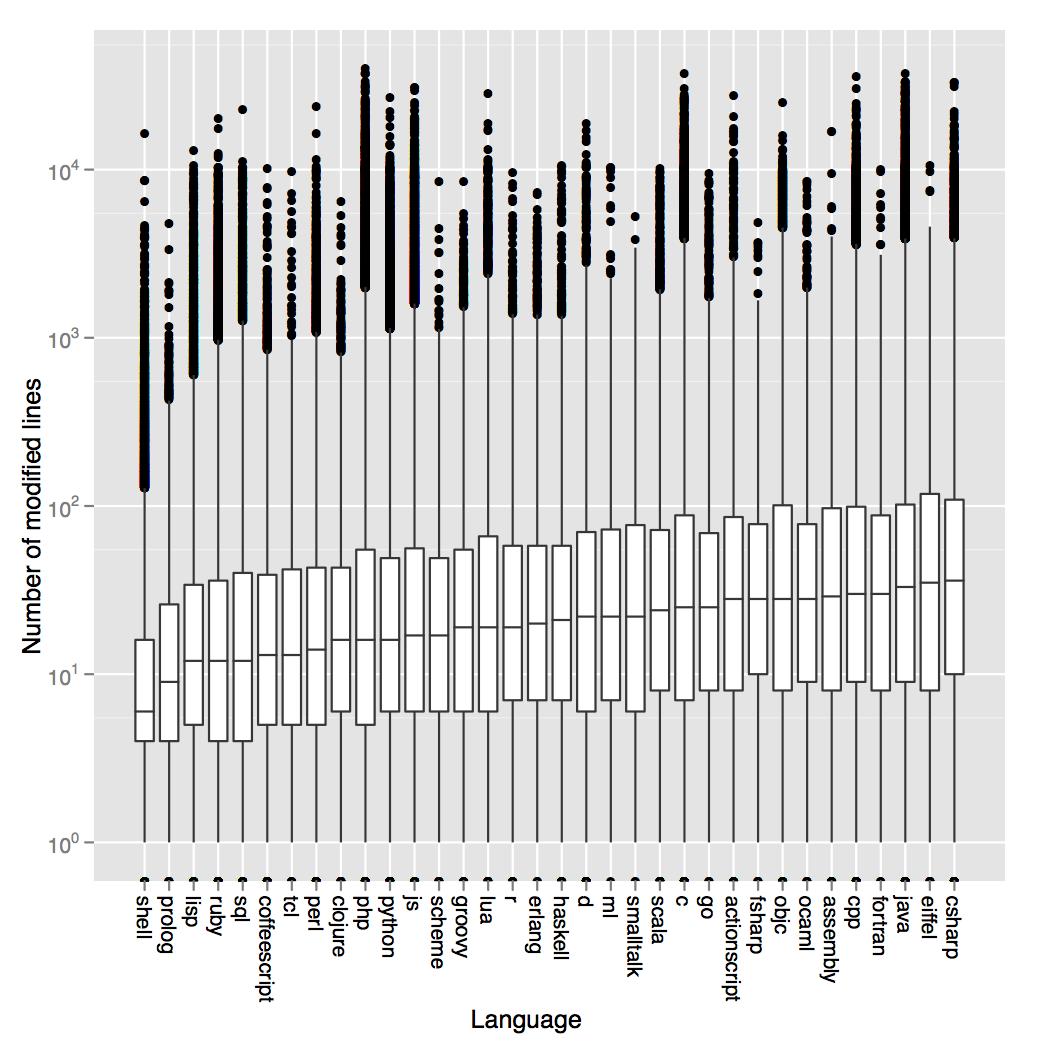
I will be careful not to make any remarks regarding the expressiveness of programming languages based on this data. The data speaks for itself and contradicts many observations Donnie included in his blog. I do believe however that the method used to extract the data is more sound as:
-
The effect of copying-pasting code, common in environments such as Javascript where developers include whole libraries to their repository, to the results is non-existent as such actions are discarded.
-
By relying on file extension matching to identify the programming language we get far more accurate results per language than relying on Github’s or Ohloh’s project language identification.